

As a good student, I’ve been spending all my time lately studying. So the only thing I’ve had time to write is study notes. I thought that I’d make the most of them, share a bit of my new knowledge with you, and give you a quick crammer’s guide to some of the topics from each of my subjects this semester. The information probably won’t mean a whole lot to you if you’ve never learnt anything about the topic before, but if you have, hopefully, this’ll clear up a few things for you.
This one’s about C Programming. This subjects covers making programs in C, pointers, file handling and parameters, generic programming and dynamic data structures.
Linked Lists
Linked lists are a special way of storing data, using a data structure that can grow or shrink as needed, and doesn’t need to be located in contiguous memory, i.e. it doesn’t all need to be next to each other in memory. It does this by using pointers to point to the next item in the list. Each item is called a node. The first node is pointed to by a special node called the head, which isn’t really a node, or an item in the list; it’s just a pointer to the rest of the list. It can store some data about the list over however, such as the number of nodes, or pointers to functions that can be used on the list.
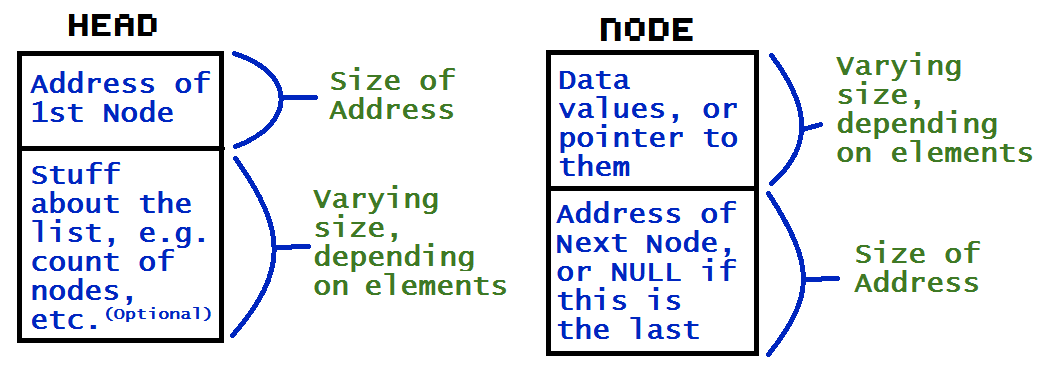
Each node has some data, or a pointer to some data, and a pointer to the next node. The last node points to NULL (nothing) so that we know when we’ve reached the end. Some linked lists (called doubly-linked lists) have nodes with a pointer to the previous node also. This can be very handy in some situation, however my studies so far have been focused on singly-linked lists.
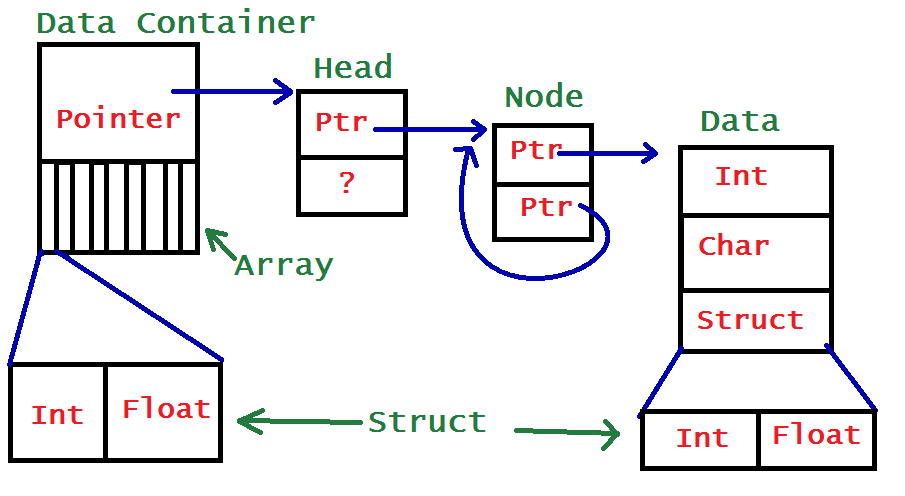
Even without doubly-linked lists, linked lists, combined with other data structures, can get pretty complex. Here’s and example of a data structure from one of my assignments this semester:
Adding Nodes
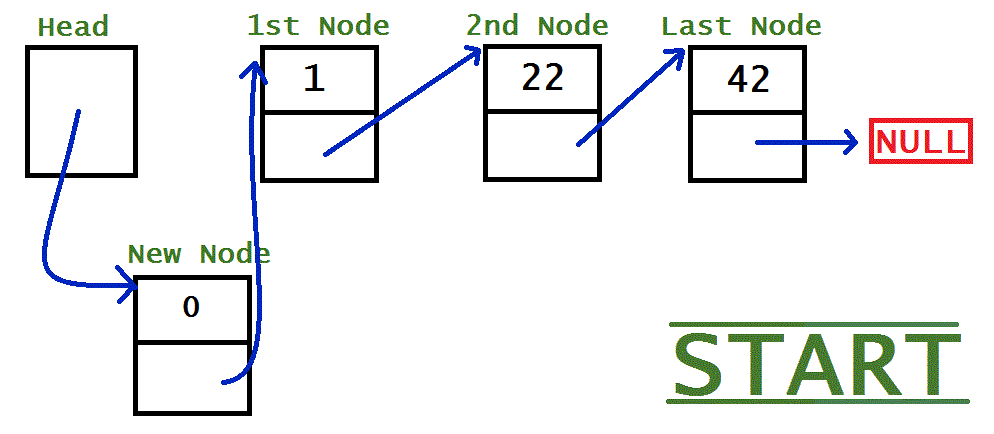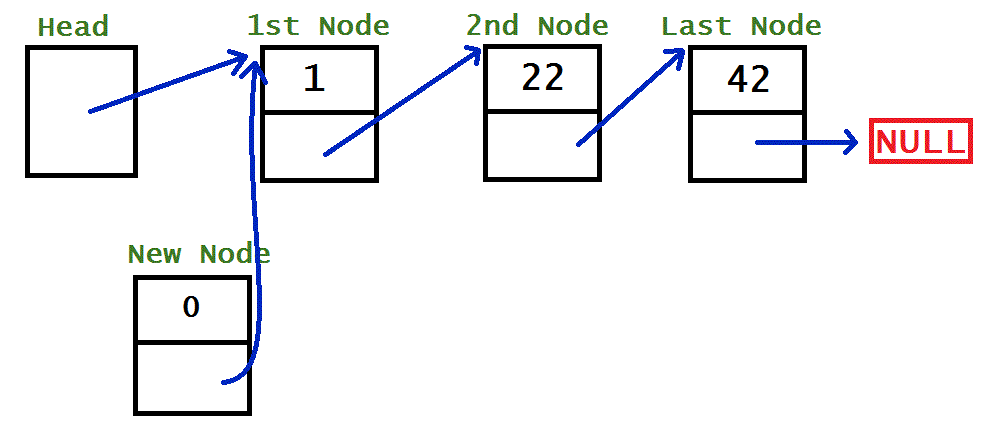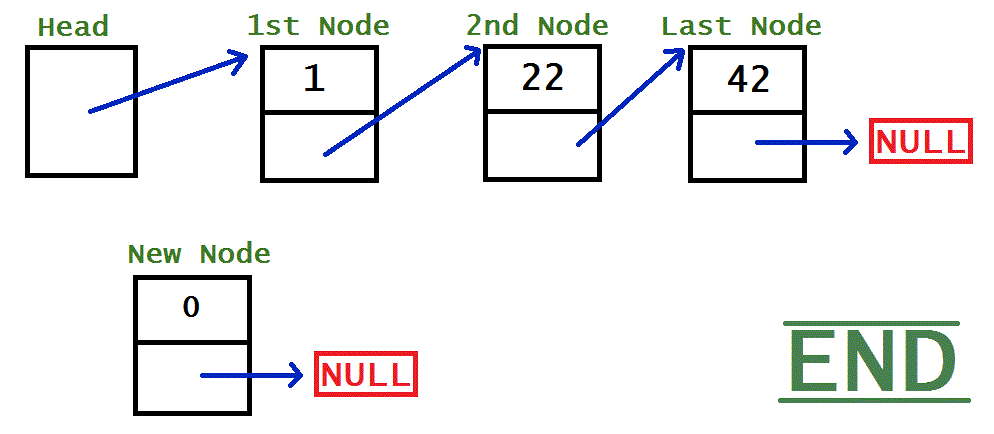
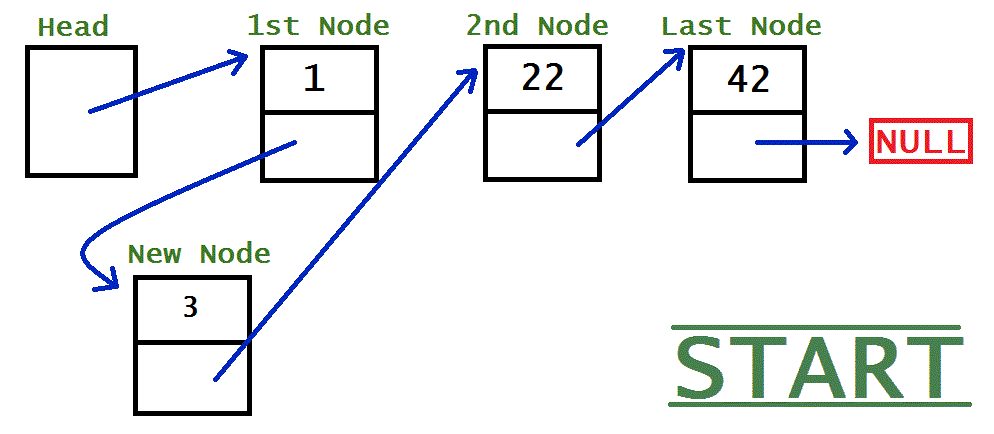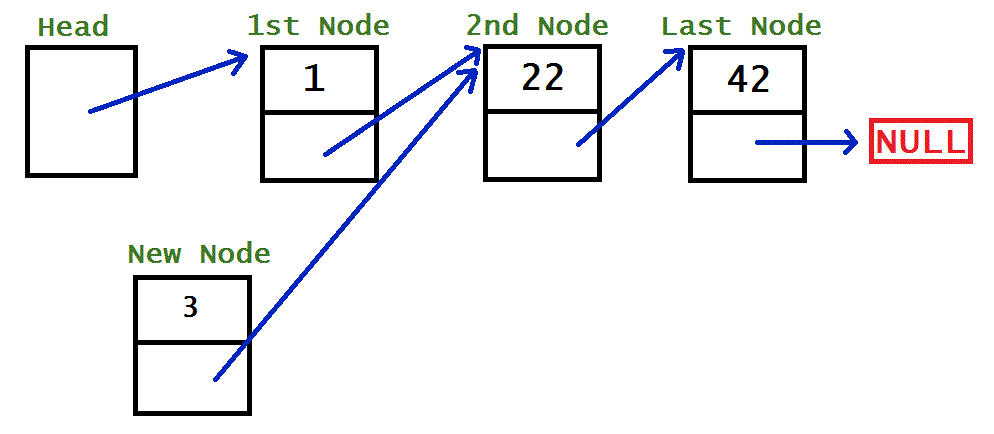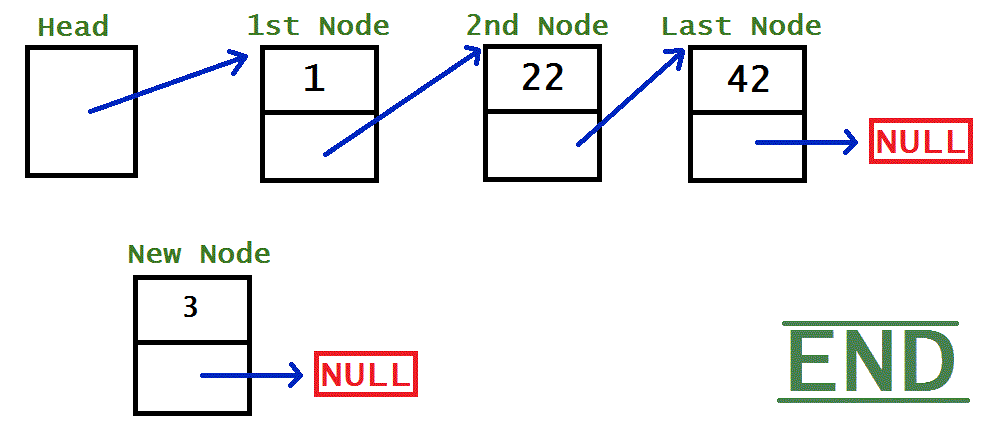
The process for adding a node to a linked list is slightly different depending on where it’s being added. Usually nodes are added in order, because there much more useful that way. Below I have three GIF images to illustrate the process for added a node in each of the different situations: Immediately after the head, Somewhere in the middle, and At the end.
HEAD

newNode.next = head.next;head.next = newNode;
MIDDLE

To add a node in the middle of a sorted list, you need to know about two nodes: the node before where it goes (previousNode), and the node after where it goes (currentNode). You don’t actually use currentNode, but you need to keep track of it, so you can check if actually is after newNode, or if newNode may need to go further down the list. (This might all make a bit more sense after you’ve read the sorting section below). Anyway, once you’ve found where to insert the newNode, this is what you have to do.
newNode.next = previousNode.next;previousNode.next = newNode;
END

If you’re linked list is well-made, adding to the end will actually be exactly the same as adding to the middle, because previousNode.next will point to NULL, so step 1 will be redundant but still work.
previousNode.next = newNode;
Removing Nodes
Removing nodes is exactly the same as adding nodes, but backwards. In fact, that’s so true, I’m using the same GIFs, but backwards!
HEAD
MIDDLE
END

Sorting Existing Linked Lists
Adding nodes to a linked lists in order isn’t too hard, but sorting an existing linked list is a whole different story. There are three sort methods(that I know about) you can use (in order of ease to code/use):
- Bubble sort – where you iterate through the list multiple times, comparing pairs of nodes next to each other, and flipping them if they’re out of order. When you’ve done a pass of the whole list without making a change, then it must be sorted.
- Selection sort – where you make a new list (head), and add nodes from the original list to it in order, then point the original head at the new list. When there are no nodes left in the original list, i.e. the original head points to NULL, you know the new list is sorted.
- Insertion sort – where you rearrange the list by dividing it into two portions, a sorted and unsorted section. Nodes are taken from the unsorted section and inserted into the sorted section in order, like if they were a new node. When there are no nodes left in the unsorted portion of the list, the list is sorted.
To see a visual representation of these different sort types, as well as many more, have a look at sorting-algorithms.com
Bubble Sort
Bubble sort is a common, inefficient algorithm for sorting things, however it is the easiest to get your head around, and especially in an exam situation, it’s the easiest to quickly and cleanly write code for.
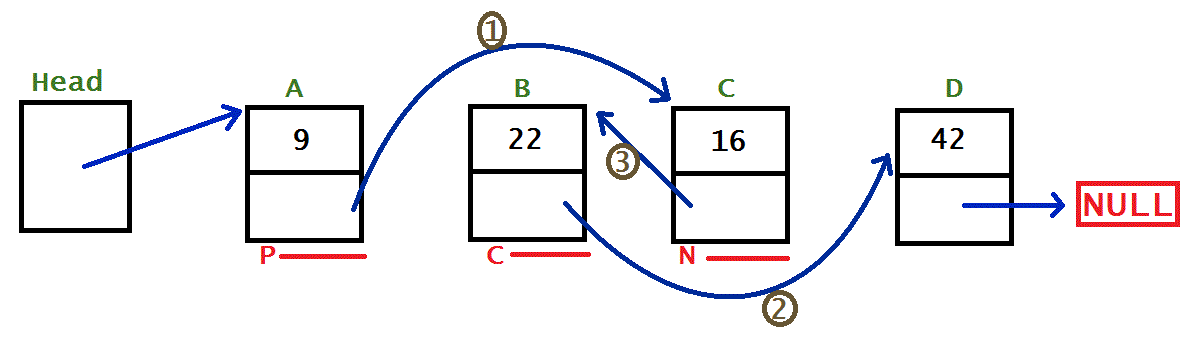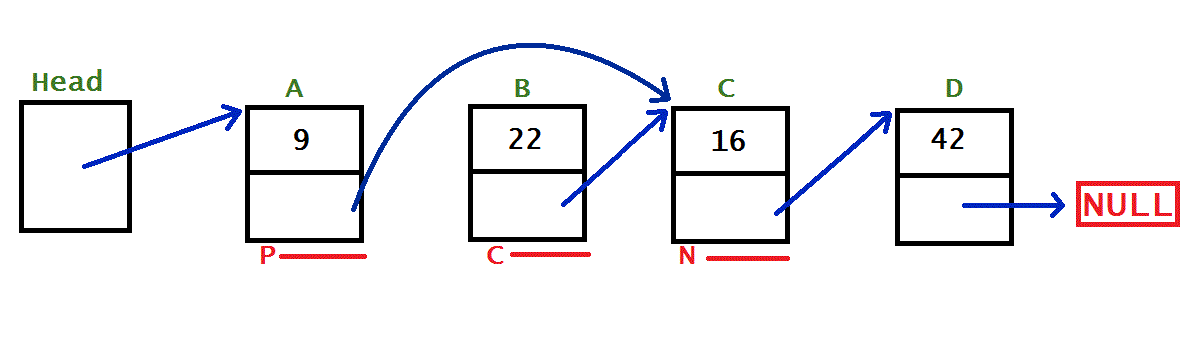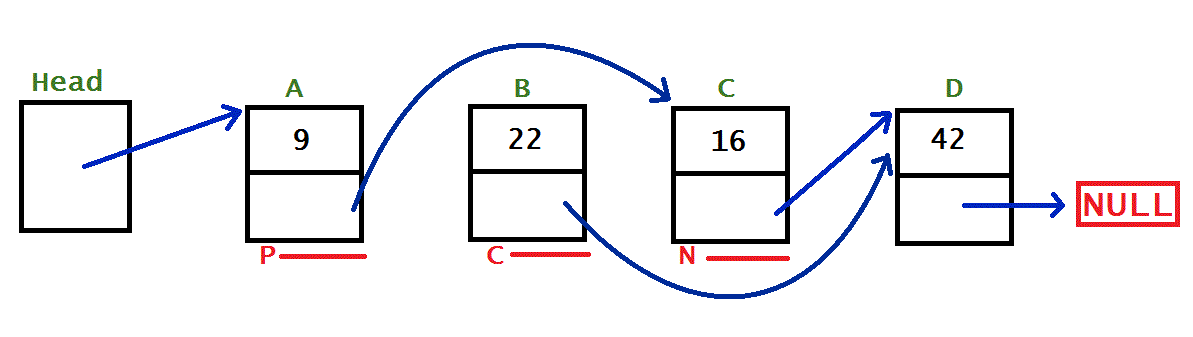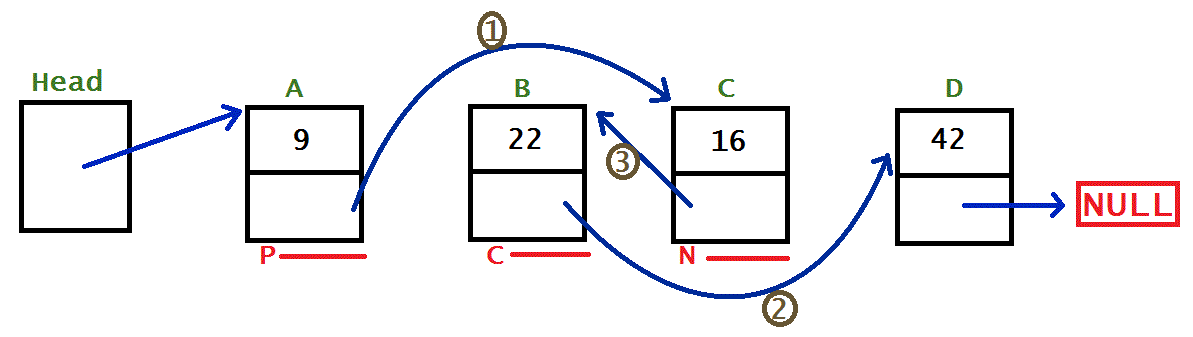
To do the bubble sort, you need to iterate through the lists, comparing pairs of nodes. To do this, we need two pointers to point to the two nodes we’re comparing, which I’ll call currentNode and nextNode. They’re shown in the image above by the nodes underlined with a C and N, respectively. Because we’re (potentially) changing the order of these nodes, we need to also have a pointer the nodes that point to these nodes. currentNode points to nextNode, so that’s fine, but we also need to track the node that points to current node; that’s where the previousNode pointer comes in, visualised by the node underlined with a P in the image above. Now that we have all that, we just need a Boolean to keep track of if an exchange (swap) was made in the last iteration, so we know if the list is sorted.
So our code will look something like this:
previousNode.next = nextNode;currentNode.next = nextNode.next;nextNode.next = currentNode;
Although the steps are numbered 1-3, there is a bit of flexibility in this order. As long as you do step 2 before step 3, it should be fine. You could do step 1 first, last or in the middle; it doesn’t matter because you’re not going to lose access to anything by changing previousNode.next.
In the image above, the linked lists is one swap away from being sorted, and that swap occurs in the middle of the list. The code for a swap at the end of the list (the last two nodes) would be exactly the same as for the middle, but a swap at the start (first two nodes after the head) would be a bit different, however the process would be exactly the same. If the exchange is happening at the start of the list, previousNode will be NULL, so as long as you check for that before using it in step 1, and have an alternative instruction that uses the head instead, it’ll be fine.
After making the swap, your pointers are all over the place. To set them up to keep going through the list, the node that was nextNode becomes previousNode, and the currentNode.next becomes nextNode. The code makes it a bit clearer:
previousNode = nextNode;
nextNode = currentNode.next;
Selection Sort
Selection sort can be broken down into two repeating phases: finding the next node, and moving that node to the new list. While moving the next node to the new list is actually easier than the swap in a bubble sort, finding which node you need to move is more complex.
Finding the next node
For this stage, you need two sets of currentNode and previousNode pointers. One set is used to traverse the list looking for the next node, while the other is used to point to the node that’s the best one found so far. So, if you were sorting the list from smallest to largest, this would be the smallest node you’ve found so far, and the node that came before it. I call these nodes currentFound and foundPrevious respectively.
At the start of each traversal, you set the first node in the list as currentFound, because otherwise you’ve got nothing to compare the other nodes to. Then you move down the list, comparing currentNode and currentFound to see which one should come next. If currentNode trumps currentFound, you set currentFound to whatever currentNode is currently pointed at. i.e. currentFound = currentNode. Once you reach the end of the list (currentNode.next = NULL), you move onto the node moving stage.
Moving the next node
For the moving section you’ll need a few extra pointers as well. For starters, you’ll need a new head. It actually isn’t a head; it’s just a pointer to the first node in the new sorted list. You’ll also need a pointer to the last node in the new list, so that you can access it quickly to attach the next node to it. I call theses two pointers fakeHead and newEnd respectively. Once you’ve got them in place, and you know what the next node to be added is (because you’ve searched the list), you’re ready to go.

previousFound.next = currentFound.next;newEnd.next = currentFound;currentFound = newEnd;
Step 1 is dependant on previousFound not being NULL; if it is NULL, then currentFound must be the first node in the list, and you would have to adjust the original head instead. Step 2 is dependant on newEnd not being NULL; if it is NULL, then this must be the first node added to the list, and so fakeHead would have to be pointed at it instead.
Once you’ve moved the node, you should check if there are any nodes left in the original list, and if not, make the original head point to the new list because you’re done. It’s sorted!
NOTE: I was originally planning on going over the workings of an insertion sort here too, but it’s fairly complex, and I’ve already spent 3 whole days working on this blog…So if you really want me to write about leave a comment, and if I get a few (1+) requests I’ll fill it in here, or put it in a separate post, and link to it here.
Dynamic Arrays
Linked Lists are great, but they’re not always the best. For example, you can’t do a binary search on them, so it can be very slow to find the data you want if you have a lot of nodes. That’s where dynamic arrays come in. They combine the dynamic sizing of a linked list with the random access of a normal array, which is needed for the binary search. However, they also require contiguous memory, i.e. all the data needs to be next to each other, which means lots of moving stuff around.
Dynamic arrays usually consist of the following:
arrayPtr– A pointer to the start of the arrayallocCount– A count of elements that memory has been allocated forusedCount– A count of elements that have been usedelemSize– A variable to represent the size of an element

So why do we need all this extra stuff for a dynamic array? Well, because it’s not actually an array in the normal sense. Think of a regular array like an ice cube tray. Each cube has its own defined boundaries, and is separated from the next one and the previous one. A dynamic array, on the other hand, is just a plastic tube or column that you freeze water in. There is no separate ice blocks. If you want a particular ice block, you have to measure (the length of an ice block × the position of the desired ice block), then you have to use a chisel to split it out.
Getting a particular element out of a dynamic array isn’t that dramatic, but it does follow that general concept. To find a particular element, you go to arrayPtr + (positionOfElement * elemSize). Depending on what your array contains, that might actually be as easy as accessing a normal array (arrayPtr[4]), but even if that’s that case, it’s good practice to still provide the elemSize variable.
Adding to a Dynamic Array
- Check if there is room for another element (
if (usedCount +1 > allocCount)) - If so, reallocate the array with more memory (
(allocCount + x) * elemSize). How much more memory you want to allocate is really up to you. There are algorithms out there about anticipating the needs for more memory, but I usually just add one or two more elements. - Find where in the array the new element goes. For an array to be truly useful, it has to be sorted.
- Shuffle all the elements after that down so there’s room.
- Insert your new element.
- Update the used counter.
Until Next Time,

Nitemice
