

Because I’ve been spending all my time studying lately, the only thing I’ve had time to write is study notes. So I thought that I’d make the most of them, share a bit of my new knowledge with you, and give you a quick crammer’s guide to some of the topics from each of my subjects this semester. The information probably won’t mean a whole lot to you if you’ve never learnt anything about the topic before, but if you have, hopefully, this’ll clear up a few things for you.
This one’s about Java Programming 2. This subjects covers graphical user interface (GUI) in Java using Swing, linked lists and binary search trees, interfaces, exceptions, and recursion.
Balancing Binary Search Trees
Binary Search Trees are a somewhat complicated data structure. They’re sort of like a Linked List if each node had two NEXT pointers instead one, giving you a tree-like structure. One pointer is RIGHT, and one is LEFT. The RIGHT pointer points to a node whose data is bigger than the current node’s data, while the LEFT pointer points to a node whose data is smaller than the current node. These nodes are called children, and the original node is called the parent. No node can have more than one parent.
The idea is that it’s easy to find a piece of data in this structure by going LEFT or RIGHT depending on if the desired item is larger or smaller than the current node’s data. This is the same principle that a binary search uses, thus the name: binary search tree.
The problem with this though, is that this design make it more difficult to add or remove data, which can leave the tree lopsided, with most of the nodes on one side. This is called unbalanced, which is defined as when “the difference in depth between the smallest and largest branches is greater than 1”. An unbalanced tree isn’t always obvious to see, but there are some cases that you can quickly spot. For example if you ever see a grandparent node (a node with a child who has a child) with only one child, then the tree is unbalanced. This situation could pretty easily be balanced by making the grandparent node a child of the parent node, and putting the parent node in the grandparent’s original position, however it isn’t always that straight forward. Below is a drawing of the described situation, and the proposed solution, with depth numbers in red to show how they differ by more than 1.

Unbalanced Binary Search Tree
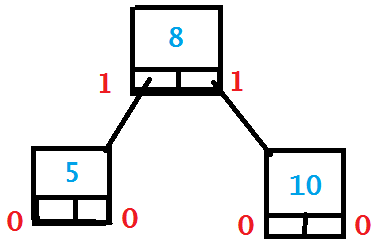
Balanced Binary Search Tree
Interface vs. Abstract Superclasses
Interfaces are an alternative to using Abstract Superclasses. There are a bunch of major differences between the two, so here’s a bit of a list:
Interfaces only contain public abstract methods (just the method signature, no implementation), which is good when you have a collection of classes that need to have a set of common methods, but may be implemented differently in each. They can’t have instance variables like a superclass can, but they can have constants if they’re declared as public static final.
Every method in an implemented interface must have an implementation in the class, i.e. you have to write something for all of them, otherwise the class must be abstract. You can’t just skip one because it’s not relevant to that class. If you find yourself in this situation, that method probably belongs in a different interface.
A class can implement multiple interfaces. This could be handy, like in the situation above so that the original interface and the new split-off interface could both be implemented by a class, compared to using superclasses where a class can only extend one superclass.
Interfaces can be treated like abstract superclasses, in that you can make an array of that type to hold any instances of a class that implements that interface. Of course, you can only access things set out in the interface through this method. So that means no access to any class-specific methods.
The idea with using interfaces is that they’re for sharing things a class does, whereas superclasses are for building upon what a class is. Here’s a dumb example: say you’ve got a class BowlerHat which inherits from an abstract superclass Hat. In Hat, you have instance variables for size and material, and methods for PutOn() and TakeOff(). You don’t need to implement any of these in BowlerHat because they are inherited, in full, from Hat. Now, say you’ve got an interface called Black, which has a method signature for BlendIn(). BowlerHat could implement Black, so that it’s a Black BowlerHat but it would have to define BlendIn() for it to work. Of course, Hats aren’t the only thing that can be Black, so you may have a Cat class which also implements Black to get a Black Cat which also has a separate definition of the BlendIn() method. Now you could put both your Black Cat and Black BowlerHat in a Black array. The Black BowlerHat could also go in a Hat array with a Pink PorkPieHat, if such a thing existed.
I hope that clarified something for you…
Recursion
Recursion is a topic a lot of people seem to have trouble understanding, but the core idea is actually a lot simpler than it may seem. In fact, if you’ve spent enough time on the internet (in the right/wrong places) you may already be familiar with recursion in the form of gifs. Nearly all gifs loop, but some loop infinitely and seamlessly. Some of these can help to illustrate part of recursion quite well. The other part, I’ll have to explain.
So, put simply, recursion is when a method involves calling itself repeatedly until the task it is performing is simplified down to nothing, so that you end up with a nesting of method calls.

There are two main parts to a recursive algorithm:
- The Recursive Step(s) – actions that are performed every time to simplify/further process the data for the possible next recursion
- The Base /Terminating Condition – the condition that determines if the method should be called again or not

Let’s try and use the above gif to explain. Say we wanted to count how many Babushka dolls we had, we could use a recursive method to do this. The method would return the number of Babushka dolls it found. In the image, the recursive step is opening the Babushka doll. Inside a Babushka doll, there may or may not be another Babushka doll. If there is another Babushka doll, then we call the method again and return whatever it returns + 1. Otherwise, the answer for this recursion is 0, so we return that. This decision is the terminating condition. As all the nested method calls return from the bottom up, the number will slowly grow until we get the total number of Babushka dolls.
Here it is in pseudo-code:
integer countBabushka()
{
Open Babushka doll
If(contains Babushka doll)
{
Return (countBabushka() +1)
}
Else{
Return 0
}
}So your question now is “when and why would I use recursion?” Well, recursion is an alternative to iteration. Think of it this way: recursion is to iteration as arraylists are to arrays. The latter is for when you know how many you need, while the former adapts to the situation at hand. Of course, you do have do-while loops which give you a happy medium, but there are certain efficiencies to using recursion.
Until Next Time,

Nitemice
Related articles
- Crammer’s Guide – Y01S01: Computer System Fundamentals (nitemice.com)
- Crammer’s Guide – Y01S01: Database Theory (nitemice.com)
- Crammer’s Edition – Maths for Computing (nitemice.com)
- Crammer’s Guide – Y01S01: Java Programming 1 (nitemice.com)
